Architecture
This article describes the recommended architecture for infrastructure that should be prepared for Collaboration Server On-Premises to run smoothly.
The following setup is recommended but not obligatory. We try to make Collaboration Server On-Premises very easy to run, but we also pay attention to its flexibility for scaling. Thanks to this, it is possible that the application works as a single instance on one server but also as many instances on many servers.
At the infrastructure level, two layers can be distinguished. The first is an application layer which is used to run the application provided as a Docker image. The second layer is responsible for all data and it is a database layer. The application layer communicates with the database layer — any server running in the application layer can retrieve the data from the database layer.
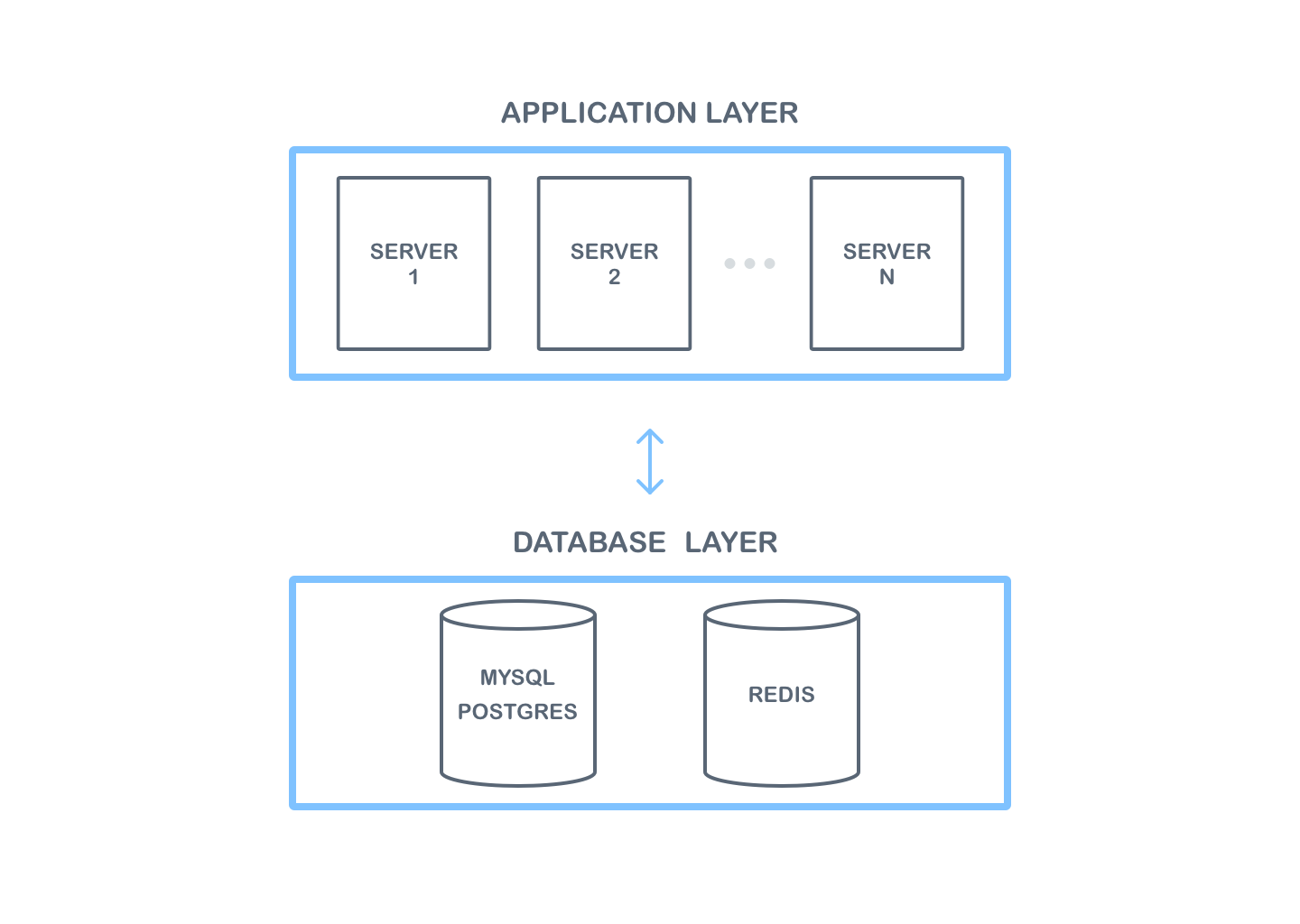
This layered architecture is recommended for security reasons. The servers in the application layer are exposed to public access. However, the databases should be run in a separate layer, i.e. on separate servers, preferably in a different subnet to which external traffic will be limited. Access to databases should only be allowed for applications running in the application layer.
The infrastructure in the application layer consists of application servers and a load balancer.
On each application server, it should be possible to run the application provided as a Docker image. To this end, it is recommended to use a containers orchestrator for clustering such as Docker Swarm, Kubernetes, etc. Thanks to this, it is possible to run and manage multiple instances of the application running on multiple application servers.
Of course, it is possible to run the application using containers orchestration available from various Cloud providers like Amazon Elastic Container Service, Azure Kubernetes Service or Google Kubernetes Engine.
Due to the fact that all application data is stored in the database layer, it is possible that every request or socket connection can be redirected to other instances of the application. Thanks to this, in case of failure of one of the instances, the application will still be available for all users. To make this possible, it is necessary to run a load balancer in front of the application servers. The load balancer should be configured to redirect requests and connections to all application servers.
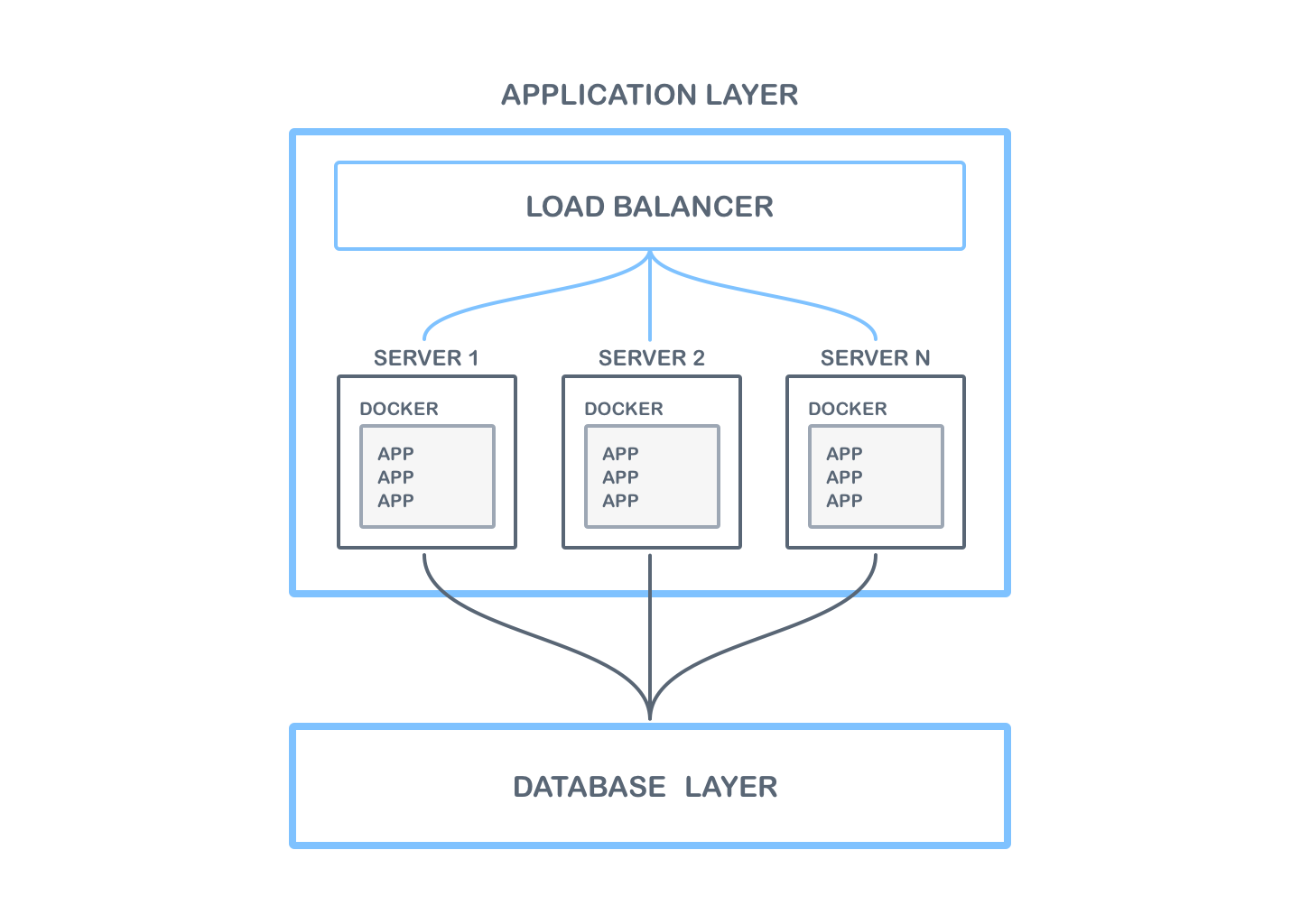
Recommendations:
- In the application layer there are at least 2 servers and at least 2 application instances should be running on each of them.
- The load balancer is configured to use the round-robin algorithm.
- The load balancer needs to support websocket connections. Refer to your load balancer documentation to verify whether websockets are supported. Some popular cloud-based load balancer solutions (e.g. Classic Load Balancer from AWS) do not allow websocket connections and cannot be used for Collaboration Server On-Premises.
The database layer consists of 2 databases.
The first of them, Redis, is used to store temporary data used in collaboration — the data is usually deleted after some time. This database is also used for scaling the application. Redis is needed for scaling because each user can connect to different instances of the application. In this case, a message delivered to one application instance via a WebSocket connection must be delivered to other instances of the application. By using this database, the application does not need to have knowledge of other application instances, because Redis handles the delivery of messages to all instances. Thanks to this behavior, no other complicated and difficult to start components are required.
The next database in the database layer is SQL (MySQL and PostgreSQL databases are currently supported). This database is used to save any data that must be saved permanently and is not needed only when a document is being edited, e.g. comments.
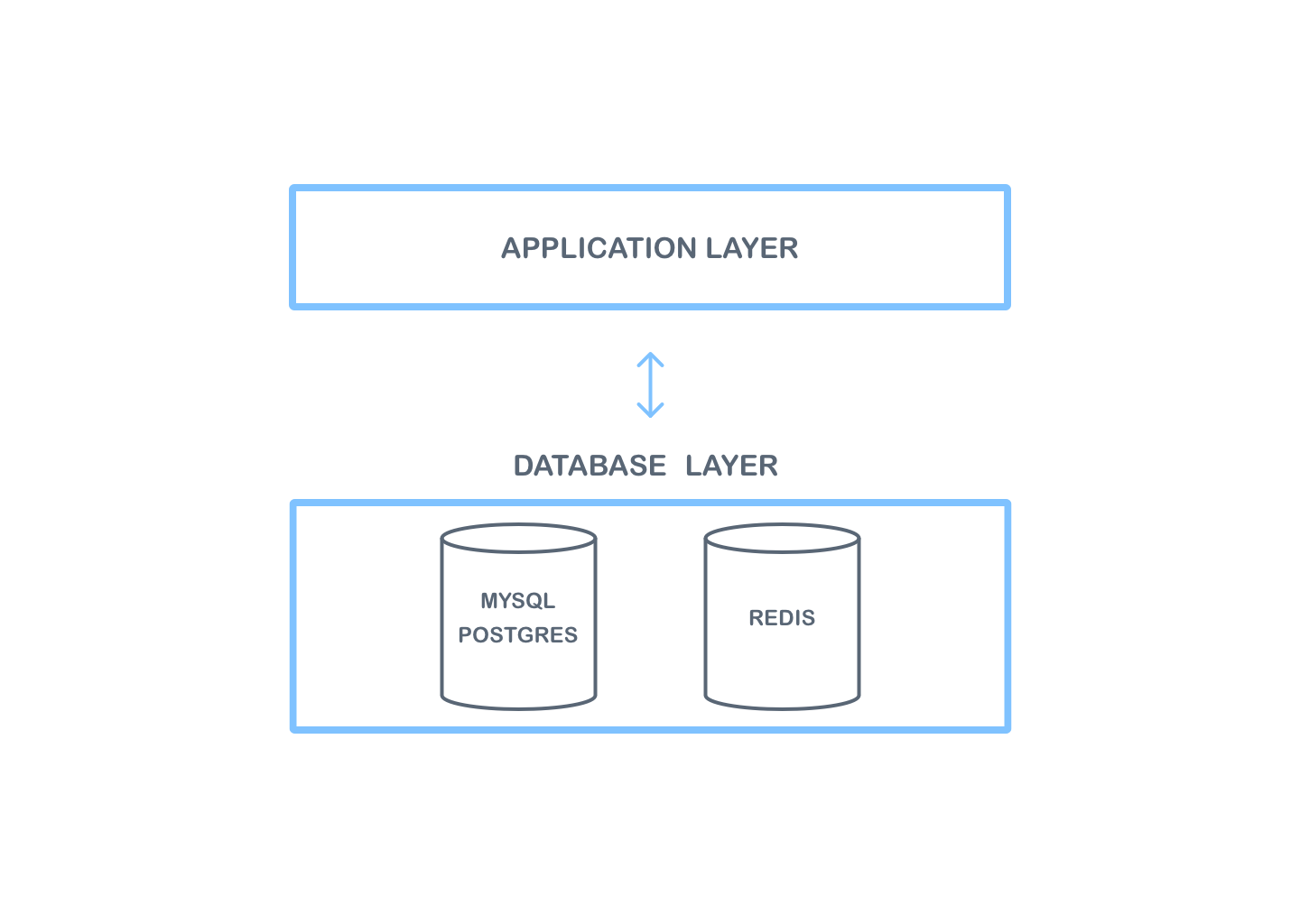
Due to different internal policies in various companies, we have decided on an approach that sets the smallest number of requirements for the infrastructure of the database layer.
The application requires only providing the access data and server addresses on which the databases are located. Database requirements are available in the Requirements section. Therefore, the databases can be run in any way — as a native installation on separate servers, using databases from any cloud providers or using Docker containers.
You should pay special attention to ensure that the data saved in the SQL database is safe and always available.
If the Docker image was used to provide the SQL database, the data must be available after a container restart.
Recommendations:
- The databases should not be publicly available.
- Prepare and test a backup mechanism.
To aid our customers in building a stable and secure service, we created a set of ready-to-use IaC scripts to set up the Collaboration Server quicker. You can use this repository as a guide on how to build your own infrastructure with recommended configuration, employing the best practices. You can also deploy the Collaboration Server On-Premises to your infrastructure provider of choice with these few simple steps.
The script will initialize the infrastructure with multiple instances, set up the load balancer and the data layer. It will automatically fetch and run the application.
Check out these examples to learn more:
If you have any questions, feel free to contact us.