How we reduced traffic 10-20 times - data compression in real-time collaboration

When you are creating a complex system from scratch, you have hundreds of problems to solve and the amount of data you send over the network is usually not the first one to be tackled. It was no different in CKEditor 5. Donald Knuth once wrote:
Premature optimization is the root of all evil.
Optimizing upfront, before we know that we actually need to, is something that we consciously avoid when building our WYSIWYG editor capable of handling features such as real-time collaboration.
Once the project matures, the moment when you need to work on some network data optimization finally comes. There might be many reasons for this. For example, you may reach the point where your system is getting slower or you may want to provide better support for users with a poor network connection.
In the case of CKEditor 5, the reason was different. Our backend is built on microservices. To support many clients and provide high availability, all microservices implement redundancy. We also use additional services for load balancing and service discovery. This setup generates a lot of traffic between the services, and the traffic is costly.
Besides server optimization, which is a nice topic for a separate article, we decided to limit the amount of data the clients send to the server. When working on it, we faced a number of problems and we would like to share our experience in the hope that it will be useful to you.
To put things into perspective, here is the comparison of the number of bytes used to send basic actions before the optimizations that we introduced in CKEditor 5, after them, and when compared to the same actions done in Google Docs.
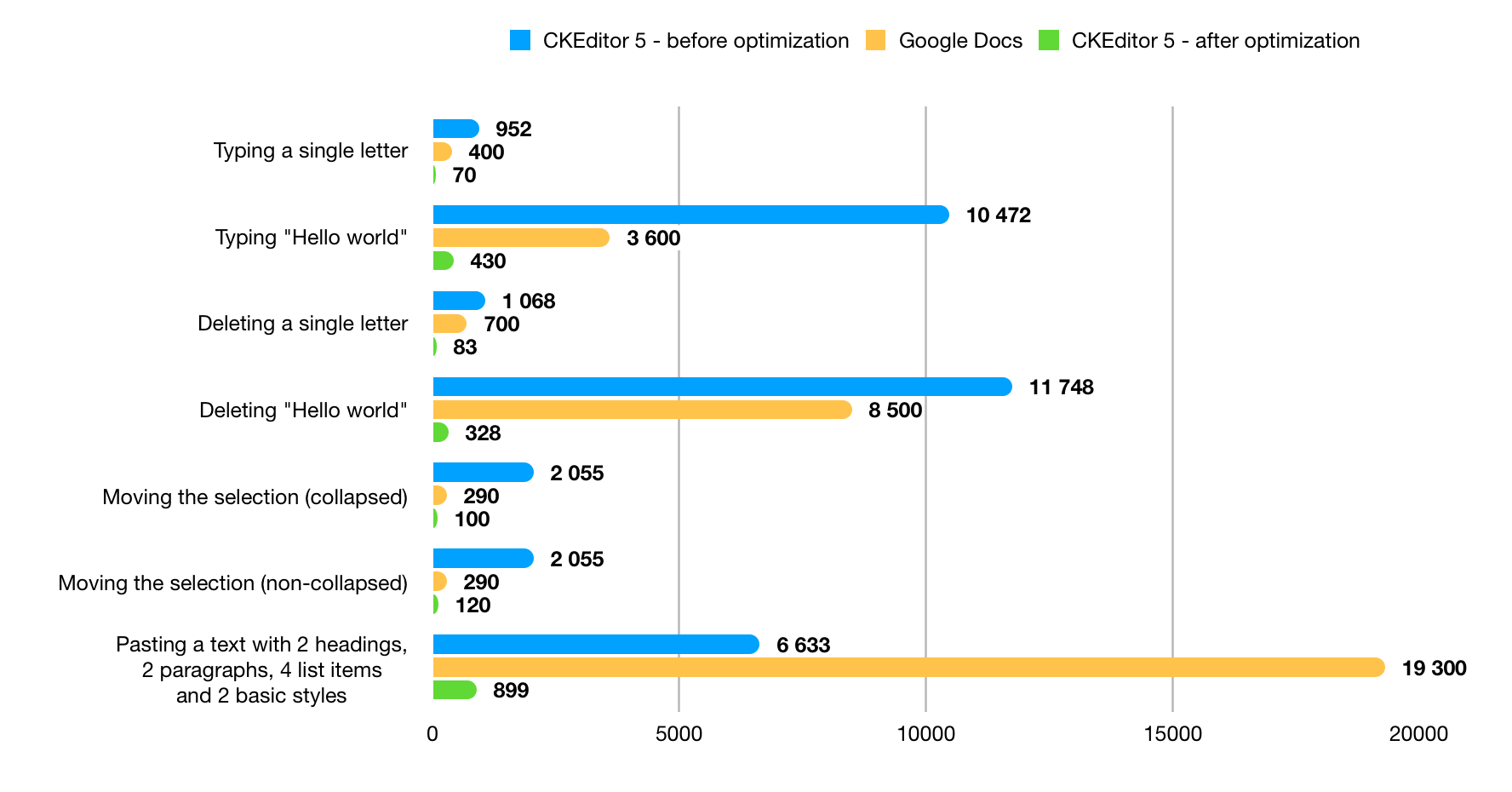
Read on to learn how we managed to achieve this.
The compression layer
The first decision to make was: What sort of data should we compress?
The first idea that we had was to rework the entire internal data structure that the editor uses on the client. CKEditor 5 uses operations (simple JavaScript objects), a concept coming from Operational Transformation, to represent every change in the document. Maybe these operations could be made smaller? It would have an additional benefit of reducing the in-memory usage of objects.
But the reality is that memory consumption is not an issue we tried to solve here. We have already spent a considerable amount of time improving it before and for sure there is still some room for improvement. This time, however, the problem is different: the amount of data we send over the network, not the amount of data we store.
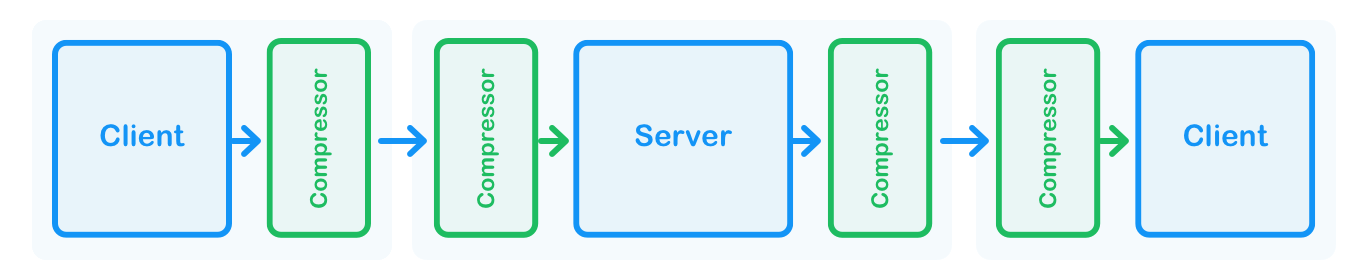
This is why we decided to try a different approach and focus solely on the transport layer. We added a data compression and decompression layer just before the data is sent and just after the data is received.
The only responsibility of this layer is to reduce the number of bytes we need to transfer the data. It does not need to care about the logic, what the data means or if it is still meaningful after the compression as long as we get the same data after the decompression. This has the following consequences:
- We have few limitations when it comes to tricks we can use to compress the data.
- This change does not touch our architecture — the operations and how we transform them.
- The whole business logic does not matter for the compressor.
- What the compressor does is transparent to the rest of the system.
Step 1: Compress keys and structure
Since we already have a compression and decompression layer defined, it is time to look at some messages we send.
Let us focus here on the most common and simplest case: typing a single letter.
Before our optimizations, when you checked a CKEditor 5 build with real-time collaboration in a network debugging tool, you would see something like this (actually this is not the exact message, it is a little simplified to make it more clear for the purpose of this article):
{
"service": "ckeditor-collaboration",
"message": {
"_type": "ckeditor:update",
"operations": [
{
"baseVersion": 15,
"position":{
"root": "main",
"path": [ 4, 184 ]
},
"nodes": [ { "data": "a" } ],
"__className": "InsertOperation"
}
]
}
}What do we have here? This is obviously a piece of JSON data.
- The first piece of information is the name of the service which will handle the data, and the type. Let us assume this is an envelope.
- Then we have the content of the message — a single operation, to be precise. The operation has the base version of the document that this operation can be applied on. Each operation increments the document version so operations from a single client will have consecutive base versions.
- The position property stores the information where the typed letter will be inserted.
- Root is the name of the root element of the document tree that the letter will be inserted into. Note that in CKEditor 5 a single editor may handle many editable areas with multiple editable roots.
- Path defines the position in the root. In this case, it is position 184 in the 4th paragraph.
- Then we have nodes to be inserted. In this case — only a single text node.
- And finally
__classNamedefines the name of the class that needs to be used during deserialization.
While this seems to be quite a minimal representation of the data, there is still a lot of things that are not actually the core of the message, like the entire overhead of the JSON format, property names, etc.
It means that the receiver does not need to get all additional data that is there for parsing reasons only:
- The data types are known for both the sender and the receiver, so they can be removed.
- We can remove all brackets, quotes, and colons.
- All keys are known for both the sender and the receiver, so we can remove them, too.
All we need to send are values and some data separators:
ckeditor-collaboration
ckeditor:update
15
main
4, 184
a
InsertOperationWhat we end up with are pure values. You can just send them, preferably in the binary format, and the receiver should understand them as long as they know which descriptor should be used.
If the order of values is fixed and you do not skip any value, it is enough to prefix each item with its length to encode the object into one string. This will make it easy to decode for the receiver:
| length | value |
|---|---|
22 |
ckeditor-collaboration |
15 |
ckeditor:update |
1 |
15 |
4 |
main |
2 |
4,184 |
1 |
a |
38 |
InsertOperation |
Figure 3. Prefixing values with their length for easier decoding.
This is basically how the Apache Avro format works.
Additionally, each item may have not only the length but also an ID. Thanks to IDs your data format is more flexible — you can skip some properties or introduce new items to your description and old values will still be readable for the receiver.
| ID | length | value |
|---|---|---|
1 |
22 |
ckeditor-collaboration |
2 |
15 |
ckeditor:update |
3 |
1 |
15 |
4 |
4 |
main |
5 |
2 |
4,184 |
6 |
1 |
a |
7 |
38 |
InsertOperation |
Figure 4. Adding an ID to make the data format extensible.
This is how the Google Protocol Buffers format works.
When performing benchmarks using the data that is most frequently sent during collaboration in CKEditor 5, both Avro and protocol buffers gained similar results, with a slight advantage of the latter. Also when looking at the adoption and maturity of both solutions, protocol buffers gained more points so we went ahead with this format. We have decided to use the Protobuf library.
I also recommend you to read this comparison between Avro, Protocol Buffer and Thrift.
Step 2: Compress values
Using protocol buffers and defining descriptors for all data types have already given us great results, but we could do even better. The next step was to compress values.
Of course, not all values can be compressed. It is hard to compress a single letter or an integer. However, there are 3 types of data you can consider compressing: enumerables, popular values, and long values.
Substitution coding
Whenever you have a closed list of possible values, you can assign each value to an integer code and use it instead. This technique is known as substitution coding (or dictionary coding) and is used in many popular compression algorithms (e.g. DEFLATE).
The dictionary that we used was fairly simple: AttributeOperation got code 1, InsertOperation got code 2, etc. This way we were able to use these codes instead of string values and save some bytes. The same could be done with the service information (ckeditor-collaboration and ckeditor:update) and we ended up with several dozen bytes less:
| (service name code) | 1: |
| (service method code) | 2: |
| (base version) | 3:15 |
| (position root name) | 4:main |
| (position path) | 5:4,184 |
| (data) | 6:a |
| (operation type) | 7: |
1:7 |
2:3 |
3:15 |
4:main |
5:4,184 |
6:a |
7:2 |
Figure 5. Substituting string values with integers.
Substitution coding for popular values
The same technique also works for items that can have any value but use some more often than others. This is the case of the position root name. In theory, it can take any value — you can create any editable root in the editor. In practice, most editors built on top of the CKEditor 5 editing framework use a single root element, called main, and a special $graveyard root to keep the removed element for undo purposes.
We had one more problem with properties that can have any value: How to represent this special value to avoid conflicts with other values? We needed something short and unique, and this is an unpopular combination.
This is why, in this case, we used the power of protocol buffers and simply skipped the root name (code 4) property. Instead, we introduced a new “main root” property (code 10), with a Boolean value. If the root name is main, this property is set to true and the root name is skipped. Otherwise, the special property is skipped and a regular root name is added with a string value:
| (service name code) | 1:7 |
1:7 |
1:7 |
| (service method code) | 2:3 |
2:3 |
2:3 |
| (base version) | 3:15 |
3:16 |
3:17 |
(position has main root) |
10:1 |
10:1 |
10:1 |
| (position path) | 5:4,184 |
5:4,185 |
5:4,186 |
| (data) | 6:a |
6:b |
6:c |
| (operation type) | 7:2 |
7:2 |
7:2 |
1:7 |
(ckeditor-collaboration) |
2:3 |
(ckeditor:update) |
3:15 |
|
10:1 |
(true) |
5:4,184 |
|
6:abc |
|
7:11 |
(InsertOperation) |
Figure 6. Substituting popular values.
When you compare it now with the JSON message we started from, you will see how huge the progress is already.
Compressing long texts
You may ask now: what about using DEFLATE or similar compression algorithms? This is, most probably, the first thing that comes to your mind when you think about compressing values. We also considered it, however, there are two issues.
The text compression algorithms work well for longer texts. The longer the value you have, the better results you can get. In the case of very short values it, in fact, makes them even longer. This is why there is no point to use such algorithms to compress short values like those in our sample.
Popular compression algorithms may also open a way for denial of service attacks. A malicious message with a few kilobytes can be crafted in such a way that it expands to hundreds of gigabytes after the decompression on the server side, which will very likely kill the service. This kind of vulnerability is known as a decompression bomb.
Moreover, such algorithms are relatively slow. They consume memory and processor time of the server whose main purpose should be to handle as many messages as it can. This basically means that this approach makes sense only for longer, preferably text, values where the net profit is worth it.
Step 3: Compress sequences
So far, we were able to improve the data compression when a single letter was inserted. This is, however, not everything that we can do to improve the data compression for typing. When we checked how the next letters are represented, we could see this:
| (service name code) | 1:7 |
1:7 |
1:7 |
(ckeditor-collaboration) |
| (service method code) | 2:3 |
2:3 |
2:3 |
(ckeditor:update) |
| (base version) | 3:15 |
3:16 |
3:17 |
|
(position has main root) |
10:1 |
10:1 |
10:1 |
(true) |
| (position path) | 5:4,184 |
5:4,185 |
5:4,186 |
|
| (data) | 6:a |
6:b |
6:c |
|
| (operation type) | 7:2 |
7:2 |
7:2 |
(InsertOperation) |
Figure 7. Representation of subsequent values in collaboration.
This is what changes:
- The base version (it gets consecutive values).
- Letter position (it gets consecutive values).
- The letter that is inserted.
And this is it. It looks like there is still huge room for improvement.
However, first we needed to send multiple letters in a single message instead of sending each operation as soon as it appears.
This is why we introduced a buffer that collects multiple operations, compresses them, and sends them together. It slows down the speed of how fast user B gets messages from user A, but it is a matter of balance between compression effectiveness and user experience.
We decided to introduce a 300 milliseconds delay. It is visible when you observe how user B receives letters from user A, but it is totally acceptable in terms of user experience. Also, it lets us squeeze 2-3 letters each time the user types.
| (service name code) | 1:7 |
1:7 |
1:7 |
| (service method code) | 2:3 |
2:3 |
2:3 |
| (base version) | 3:15 |
3:16 |
3:17 |
(position has main root) |
10:1 |
10:1 |
10:1 |
| (position path) | 5:4,184 |
5:4,185 |
5:4,186 |
| (data) | 6:a |
6:b |
6:c |
| (operation type) | 7:2 |
7:2 |
7:2 |
1:7 |
(ckeditor-collaboration) |
2:3 |
(ckeditor:update) |
3:15 |
|
10:1 |
(true) |
5:4,184 |
|
6:abc |
|
7:11 |
(InsertOperation) |
Figure 8. Compressing sequences thanks to buffering.
We introduced a new type of message, InsertMultipleChars, very similar to the typing message. It sends all letters as a single string (even though they were inserted as separate operations). Based on the length of this string we know how many insert operations we need to recreate during the decompression process on the other client. Positions and base versions are very easy to recreate based on the first value.
Thanks to this we are able to send an almost 3 times smaller amount of data.
Step 4: Additional optimization
The example above only shows typing, however, we did similar deep optimizations also for deleting and moving the selection as these are the most popular actions the users do when editing the document. We also introduced descriptors for all types of operations we send to avoid sending any keys. Combining multiple operations into batches was implemented for all types of operations.
But there is even more we have done:
- The server that broadcasts each message to all connected clients does not send the data to the sender.
- If there is only one connected user, we limit the amount of data they send to the server. We need to send the content to the server to make sure everything will work smoothly when the second client connects, but we do not send the user position in such case as it is not that important. We send it as soon as the second user appears.
Results
Thanks to all the optimizations above we got the following results that we were really happy with. We compared the number of bytes used to send basic actions before and after the change and additionally compared it with the same actions executed in Google Docs. A table with data says more than 1000 words, so here are our results:
| CKEditor 5 - before optimization | CKEditor 5 - after optimization | Google Docs | |
|---|---|---|---|
| Typing a single letter | 952 |
70 |
700 |
| Typing "Hello world" | 10472 |
430 |
3600 |
| Deleting a single letter | 1068 |
83 |
700 |
| Deleting "Hello world" | 11748 |
328 |
8500 |
| Moving the selection (collapsed) | 2055 |
100 |
290 |
| Moving the selection (non-collapsed) | 2055 |
120 |
290 |
| Pasting a text with 2 headings, 2 paragraphs, 4 list items and 2 basic styles | 6633 |
899 |
19300 |
Figure 9. The number of bytes sent in collaboration in CKEditor 5 before and after the changes, compared with Google Docs.
Summary
We still have some ideas for how the data compression in real-time collaboration could be improved even more in the future. However, at the moment we feel that we achieved our goal. Reducing the size of data sent during collaboration 10-20 times with no information loss brings benefits for both users and us:
- The user gets much smaller messages, which means that collaboration will work well even with a poor internet connection.
- We have much less traffic between microservices and much smaller data to store in the database. This significantly reduces the cost of collaboration and lets us propose better prices for customers using collaboration on our cloud. It is also much cheaper for the clients who decide to use the “on-premises” solution.
After a good time spent with data compression, I feel that sending data to your server is like talking to someone who you know very well. You do not need to talk much to be understood. In fact, there are very few words you need to say to be on the same page. You can skip all formal introductions and sophisticated sentences. You keep it simple and focused on the information that does matter. It is exactly the same for client-server communication.
If you would like to learn more about how we approached collaborative editing when working on the new CKEditor version, check Lessons learned from creating a rich-text editor with real-time collaboration.
You can see all collaboration features, including comments, track changes and real-time collaborative editing, in action here. CKEditor 5 Collaboration Features can be integrated into any software solution to give your users a great experience when working on content together.
You can read more on the topic of collaboration in our blog posts:
- CKEditor helps: Collaborative policy in government
- The keys for an optimal digital employee experience
- CKEditor 5 Collaboration Features v17.0.0 with new comments API
- 5 best collaborative writing strategies for 2022
- Collaboration journey of CKEditor 5 - What were we up to
- Bringing collaborative editing to any application
- 7 reasons why your LMS needs a better and collaborative WYSIWYG editor
- Lessons learned from creating a rich-text editor with real-time collaboration
Tags:


